
Decoding BERT’s pre-training
One of the most impressive feats of TL can be observed in BERT, a pre-trained model that revolutionized the NLP landscape. Two fundamental training tasks drive BERT’s robust understanding of language semantics and relationships: masked language modeling (MLM) and next sentence prediction (NSP). Let’s break them down and see how each one contributes to BERT’s language processing abilities.
MLM
MLM (visualized in Figure 12.4) is a key component of BERT’s pre-training process. In essence, MLM works by randomly replacing approximately 15% of the words in the input data with a special (MASK) token. It’s then up to BERT to figure out which word was replaced, essentially filling in the blank. Think of it as a sophisticated game of Mad Libs that BERT plays during its training. If we were to take a sentence such as “Stop at the light,” MLM might replace “light” with (MASK), prompting BERT to predict the missing word:
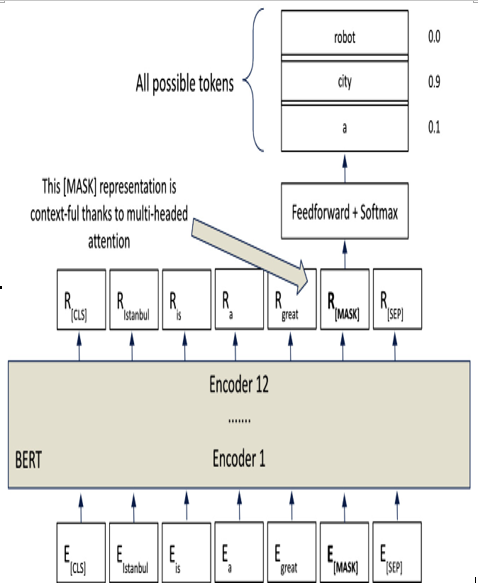
Figure 12.4 – The MLM pre-training task has BERT filling in missing tokens from a sequence of tokens
This process of MLM helps BERT understand the context around each word and construct meaningful relationships between different parts of a sentence.
NSP
NSP (visualized in Figure 12.5) is the second crucial part of BERT’s pre-training regimen. NSP is a binary classification problem, where BERT is tasked with determining whether a provided sentence B follows sentence A in the original text. In the grand scheme of language understanding, this is like asking BERT to understand the logical flow of sentences in a piece of text. This ability to predict whether sentence B logically follows sentence A allows BERT to understand more nuanced, higher-level linguistic structures and narrative flows:
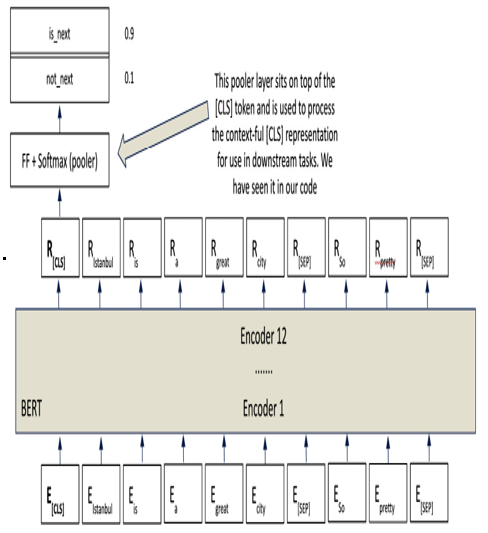
Figure 12.5 – In the NSP pre-training task, BERT is looking at two thoughts and deciding if the second phrase would come directly after the first phrase
Put another way, MLM helps BERT get a grasp on intricate connections between words and their contexts, while NSP equips BERT with an understanding of the relationships between sentences. It’s this combination that makes BERT such a powerful tool for a range of NLP tasks. Between NSP and MLM (Figure 12.6), BERT’s training is meant to give it a sense of how tokens affect phrase meanings (MLM) and how phrases work together to form larger thoughts (NSP):
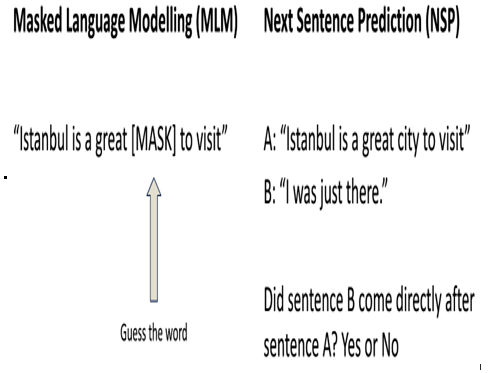
Figure 12.6 – BERT’s pre-training helps it to learn about language in general
TL
Now that we have a strong grasp of pre-trained models, let’s shift our attention toward the other compelling facet of this equation: TL. In essence, TL is the application of knowledge gained from one problem domain (source) to a different but related problem domain (target).
The process of TL
TL is all about adaptability. It takes a model that’s been trained on one task and adapts it to perform a different but related task. They might not have solved that particular mystery before, but their skills and experience can be adapted to the task at hand. TL is particularly useful when we have a small amount of data for our specific task or when our task is very similar to the one the original model was trained on. In these situations, TL can save time and resources while boosting our model’s performance.