
Different types of TL
Let’s take a moment to get familiar with the diverse landscape of TL. It’s not a single monolithic idea, but rather a collection of varied strategies that fall under one umbrella term. There’s a type of TL for just about every scenario you might come across.
Inductive TL
First up, we have inductive TL (ITL). This is all about using what’s already been learned and applying it in new, but related, scenarios. The key here is the generalization of learned features from one task—let’s call this the source task—and then fine-tuning them to perform well on another task—the target task.
Imagine a model that’s spent its virtual lifetime learning from a broad text corpus, getting to grips with the complexities of language, grammar, and context. Now, we have a different task on our hands: SA on product reviews. With ITL, our model can use what it’s already learned about language and fine-tune itself to become a pro at detecting sentiment. Figure 12.7 visualizes how we will approach ITL in a later section. The main idea is to take a pre-trained model from a model repository such as HuggingFace and perform any potential model modifications for our task, throw some labeled data at it (like we would any other ML model), and watch it learn:
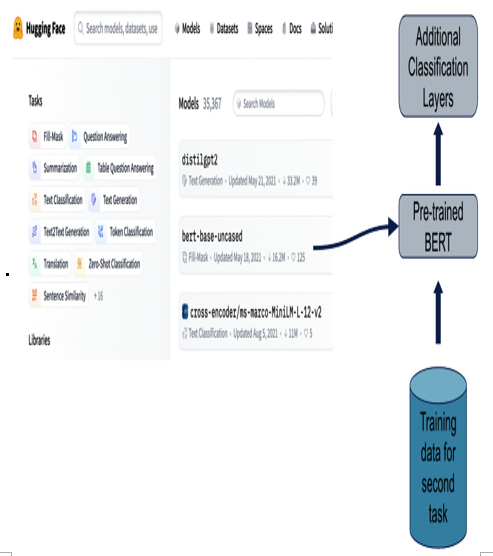
Figure 12.7 – An ITL process might involve training BERT on supervised labeled data
Transductive TL
Our second type of TL is called transductive TL (TTL) and is a bit more nebulous in its task. Rather than being given a concrete second task to perform (such as classification), our model instead is asked to adapt to new data without losing its grounding in the original task. It’s a good choice when we have a bunch of unlabeled data for our target task.
For example, if a model was trained on one image dataset to identify different objects and we have a new, unlabeled image dataset, we could ask the model to use its knowledge from the source task to label the new dataset, even without any explicit labels provided.
Unsupervised TL – feature extraction
Pre-trained models aren’t just useful for their predictive abilities. They’re also treasure troves of features, ripe for extraction. Using unsupervised TL (UTL), our model, which was trained on a vast text corpus, can use its understanding of language to find patterns and help us divide the text into meaningful categories. Feature extraction with pre-trained models involves using a pre-trained model to transform raw data into a more useful format—one that highlights important features and patterns.
These are the three main flavors of TL, each with its own approach and ideal use cases. In the wide world of ML, it’s all about picking the right tool for the job, and TL definitely gives us a whole toolbox to choose from. With this newfound understanding of TL, we’re well equipped to start putting it into practice. In the next section, we’ll see how TL and pre-trained models can come together to conquer new tasks with ease.