
TL with BERT and GPT
Having grasped the fundamental concepts of pre-trained models and TL, it’s time to put theory into practice. It’s one thing to know the ingredients; it’s another to know how to mix them into a delicious dish with them. In this section, we will take some models that have already learned a lot from their pre-training and fine-tune them to perform a new, related task. This process involves adjusting the model’s parameters to better suit the new task, much like fine-tuning a musical instrument:
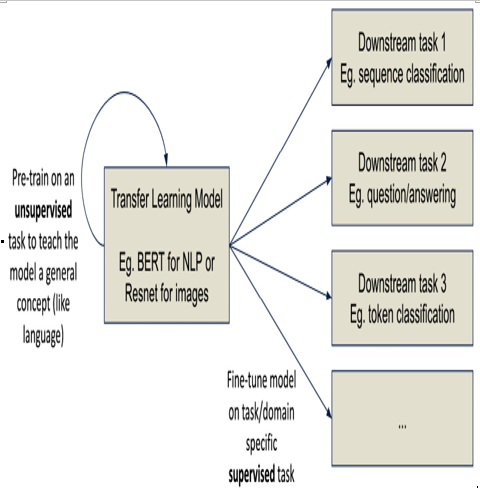
Figure 12.8 – ITL
ITL takes a pre-trained model that was generally trained on a semi-supervised (or unsupervised) task and then is given labeled data to learn a specific task.
Examples of TL
Let’s take a look at some examples of TL with specific pre-trained models.
Example – Fine-tuning a pre-trained model for text classification
Consider a simple text classification problem. Suppose we need to analyze customer reviews and determine whether they’re positive or negative. We have a dataset of reviews, but it’s not nearly large enough to train a deep learning (DL) model from scratch. We will fine-tune BERT on a text classification task, allowing the model to adapt its existing knowledge to our specific problem.
We will have to move away from the popular scikit-learn library to another popular library called transformers, which was created by HuggingFace (the pre-trained model repository I mentioned earlier) as scikit-learn does not (yet) support Transformer models.
Figure 12.9 shows how we will have to take the original BERT model and make some minor modifications to it to perform text classification. Luckily, the transformers package has a built-in class to do this for us called BertForSequenceClassification:
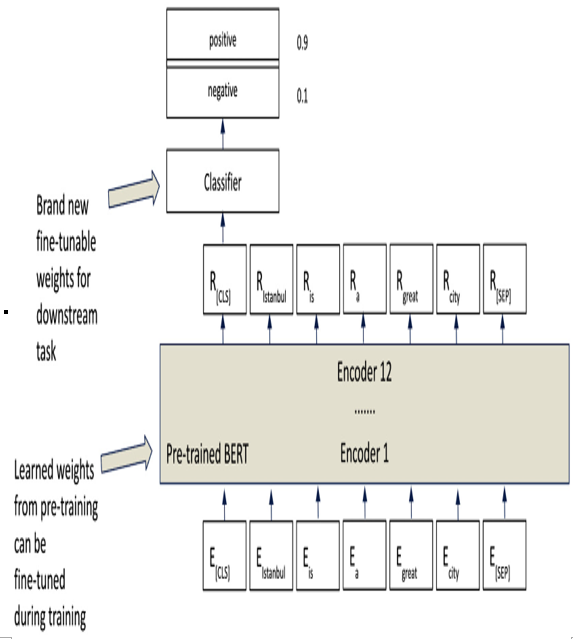
Figure 12.9 – Simplest text classification case
In many TL cases, we need to architect additional layers. In the simplest text classification case, we add a classification layer on top of a pre-trained BERT model so that it can perform the kind of classification we want.
The following code block shows an end-to-end code example of fine-tuning BERT on a text classification task. Note that we are also using a package called datasets, also made by HuggingFace, to load a sentiment classification task from IMDb reviews. Let’s begin by loading up the dataset:
# Import necessary libraries
from datasets import load_dataset
from transformers import BertTokenizer, BertForSequenceClassification, Trainer, TrainingArguments
# Load the dataset
imdb_data = load_dataset(‘imdb’, split=’train[:1000]’) # Loading only 1000 samples for a toy example
# Define the tokenizer
tokenizer = BertTokenizer.from_pretrained(‘bert-base-uncased’)
# Preprocess the data
def encode(examples):
return tokenizer(examples[‘text’], truncation=True, padding=’max_length’, max_length=512)
imdb_data = imdb_data.map(encode, batched=True)
# Format the dataset to PyTorch tensors
imdb_data.set_format(type=’torch’, columns=[‘input_ids’, ‘attention_mask’, ‘label’])
With our dataset loaded up, we can run some training code to update our BERT model on our labeled data:
# Define the model
model = BertForSequenceClassification.from_pretrained(
‘bert-base-uncased’, num_labels=2)
# Define the training arguments
training_args = TrainingArguments(
output_dir=’./results’,
num_train_epochs=1,
per_device_train_batch_size=4
)
# Define the trainer
trainer = Trainer(model=model, args=training_args, train_dataset=imdb_data)
# Train the model
trainer.train()
# Save the model
model.save_pretrained(‘./my_bert_model’)
Once we have our saved model, we can use the following code to run the model against unseen data:
from transformers import pipeline
# Define the sentiment analysis pipeline
nlp = pipeline(‘sentiment-analysis’, model=model, tokenizer=tokenizer)
# Use the pipeline to predict the sentiment of a new review
review = “The movie was fantastic!
I enjoyed every moment of it.”
result = nlp(review)
# Print the result
print(f”label: {result[0][‘label’]}, with score: {round(result[0][‘score’], 4)}”)
# “The movie was fantastic
!
I enjoyed every moment of it.”
# POSITIVE: 99%