
Understanding pre-trained models
Pre-trained models are like learning from the experience of others. These models have been trained on extensive datasets, learning patterns, and features that make them adept at their tasks. Think of it as if a model has been reading thousands of books on a subject, absorbing all that information. When we use a pre-trained model, we’re leveraging all that prior knowledge.
In general, pre-training steps are not necessarily “useful” to a human, but it is crucial to a model to simply learn about a domain and about a medium. Pre-training helps models learn how language works in general but not how to classify sentiments or detect an object.
Benefits of using pre-trained models
The benefits of using pre-trained models are numerous. For starters, they save us a lot of time. Training a model from scratch can be a time-consuming process, but using a pre-trained model gives us a head start. Furthermore, these models often lead to better performance, especially when our dataset is relatively small. The reason? Pre-trained models have seen much more data than we usually have at our disposal, and they’ve learned a lot from it.
Figure 12.1 shows the result of a study done on large language models (LLMs) such as BERT where one of the goals was to show that pre-training was leading to some obvious patterns in how BERT was recognizing basic grammatical constructs. The study visualized that models post pre-training were able to recognize what we would consider as obvious grammatical patterns, such as pronoun-antecedent relationships and direct object/verb relationships:
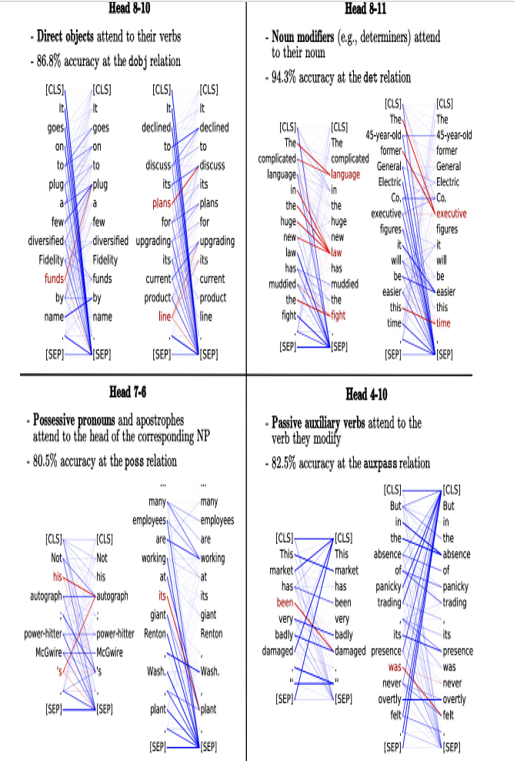
Figure 12.1 – A study visualizing how BERT’s pre-training allowed it to pick up on common grammatical constructs without ever being told what they were
BERT, of course, is not the only model that undergoes pre-training, and this practice is not even limited to text-based models.
Commonly used pre-trained models
Pre-trained models come in all shapes and sizes, each tailored to different types of data and tasks. Let’s talk about some of the most popular ones.
Image-based models
For tasks related to images, models such as the Vision Transformer (more on this one later in this chapter), models from the Visual Geometry Group (VGG) (as seen in Figure 12.2), and ResNet are some common options to choose from. Models from these families have been trained on tens of thousands of images, learning to recognize everything from shapes and textures to complex objects. They’re incredibly versatile and can be fine-tuned for a wide array of image-based tasks:
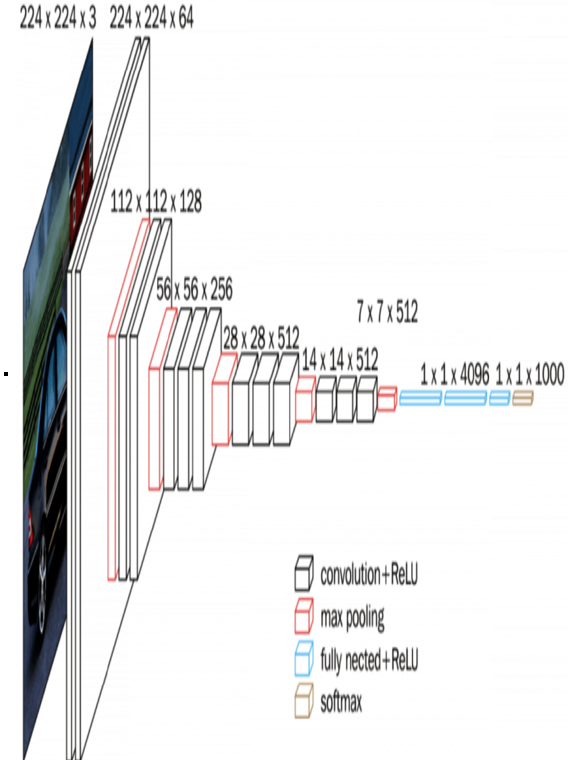
Figure 12.2 – The VGG16 model (from the VGG) is a convolutional neural network (CNN) that can be pre-trained on image data
Text-based models
When it comes to text, models such as BERT (Figure 12.3) and GPT are among the most used language models. They were first originally architected in 2018 (only 1 year after the primary Transformer architecture that both GPT and BERT are based on was even proposed or mentioned), and they’ve, as with their image counterparts, been trained on vast amounts of text data, learning the intricacies of human language. Whether it’s understanding the sentiment behind a tweet or answering questions about a piece of text, these models are up to the task. As we move forward, we’ll see how these pre-trained models can be combined with TL to tackle new tasks with impressive efficiency:
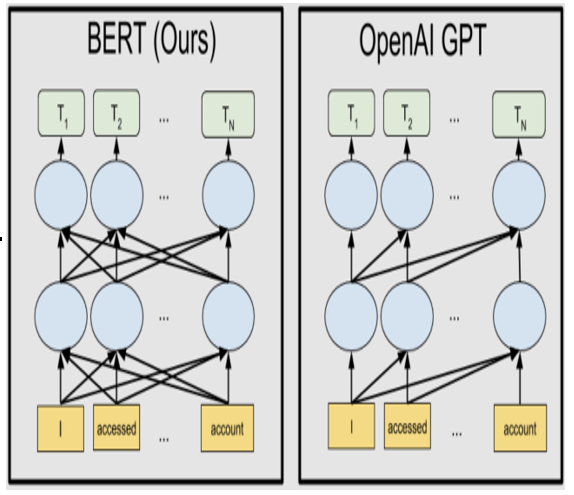
Figure 12.3 – A figure from the original blog post from Google open sourcing BERT in 2018 calls out OpenAI’s GPT-1 model
This came out a few months prior, highlighting BERT’s ability to process more relationships between tokens with the relatively same number of parameters than GPT.